Integration of LVM with Hadoop-Cluster using AWS Cloud

Let’s understand few concepts related to our task🧐
What is LVM? Why we use it?
💁🏻♀️Logical Volume Management enables the combining of multiple individual hard drives or disk partitions into a single volume group (VG). That volume group can then be subdivided into logical volumes (LV) or used as a single large volume. Regular file systems, such as EXT3 or EXT4, can then be created on a logical volume.
💁🏻♀️The EXT2, 3, and 4 filesystems all allow both offline (unmounted) and online (mounted) resizing when increasing the size of a filesystem, and offline resizing when reducing the size.
💁🏻♀️LVM helps to provides Elasticity to the storage device and it’s an advanced version of partition.
💁🏻♀️In the below figure, two complete physical hard drives and one partition from a third hard drive have been combined into a single volume group. Two logical volumes have been created from the space in the volume group, and a filesystem, such as an EXT3 or EXT4 filesystem has been created on each of the two logical volumes.

What is Elasticity?
👩🏻🏫Do you remember what our college physics had taught us about elasticity🤔Let me define it 👉🏻The property of a substance that enables it to change its length, volume, or shape in direct response to a force affecting such a change and to recover its original form upon the removal of the force is called Elasticity.
Difference between static and dynamic partition💡
💁🏻♀️There are two Memory Management Techniques: Contiguous, and Non-Contiguous. In Contiguous Technique, executing process must be loaded entirely in the main memory. Contiguous Technique can be divided into:
- Fixed (or static) partitioning
- Variable (or dynamic) partitioning
I) Fixed Partitioning:
💁🏻This is the oldest and simplest technique used to put more than one process in the main memory. In this partitioning, a number of partitions (non-overlapping) in RAM are fixed but the size of each partition may or may not be the same. As it is a contiguous allocation, hence no spanning is allowed. Here partitions are made before execution or during system configure.
II)Variable(Dynamic) Partitioning –
It is a part of the Contiguous allocation technique. It is used to alleviate the problem faced by Fixed Partitioning. In contrast with fixed partitioning, partitions are not made before the execution or during system configure. Various features associated with variable Partitioning-
- Initially, RAM is empty and partitions are made during the run-time according to the process’s need instead of partitioning during system configure.
- The size of the partition will be equal to the incoming process.
- The partition size varies according to the need of the process so that the internal fragmentation can be avoided to ensure efficient utilization of RAM.
- The number of partitions in RAM is not fixed and depends on the number of incoming processes and Main Memory’s size.

Task Description 📄
🌀7.1: Elasticity Task
🔅Integrating LVM with Hadoop and providing Elasticity to Data Node Storage
🔅Increase or Decrease the Size of dynamic partition in Linux using LVM storage.
Now let’s jump to the practical part👇🏻
Step 1: Integrating LVM with Hadoop and providing Elasticity to Data Node Storage.
Firstly we need to configure Data Node on AWS portal
While launching Data Node I am going to attach two more hard disks for LVM.

Here we can see that my both instances for data and master node are launched successfully

Now we need to configure HDFS cluster
Inside Master Node
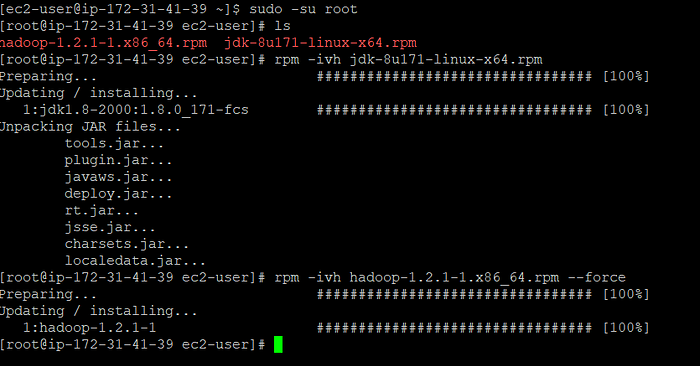
We need softwares of hadoop and java to set up hadoop cluster
Now we will configure the core-site.xml file inside cd /etc/hadoop folder

Inside the master node, we gave neutral-IP 0.0.0.0 you can say that it is a default gateway to reach/connect to any other system IP both privately and publicly.
In my case I am using Port No: 9001 you can check from your system which port no is available by using #netstat -tnlp

Now let’s configure hdfs-site.xml file

Before connecting any data node or using any storage we need to format the master node directory using #hadoop namenode -format

Now to start services of the master node we use #hadoop-daemon.sh start namenode and we can verify it by using #jps command

Now master node is configured let’s configure the data node in this node core-site.xml is configured exactly the same as the name node only IP changes.
Inside Data Node
Here also firstly install both softwares and then configure core-site.xml inside cd /etc/hadoop folder

Let us configure the hdfs-site.xml file

Now to start services of data node we use #hadoop-daemon.sh start datanode and we can verify it by using #jps command

Hence,HDFS i.e hadoop cluster is configured successfully👍🏻 we can verify by using command : #hadoop dfsadmin -report

Now let’s move to our main task of LVM
Here we can check total number of hard disks we have attached by using command : #fdisk -l

LVM architecture💁♀️

Now we need to convert our Physical H.D to Physical Volume(PV). Because VG(Volume Group) only understands in PV format.
To create a PV we use command : #pvcreate /dev/xvdc & To Confirm and display our PV we use command: #pvdisplay /dev/xvdc

To create a PV we use command : #pvcreate /dev/xvdb & To Confirm and display our PV we use command: #pvdisplay /dev/xvdb

Now let’s combine these both PV’s and form one VG of 16GiB using this command: #vgcreate arthvg /dev/xvdc /dev/xvdb

Here we got new storage or H.D of nearly 16GiB because some of the parts are already reserved for the inode table to store its metadata. Here metadata means data about data i.e data about our storage.
Let’s do a partition of this new H.D/storage/Logical Volume
Creating a partition let’s say of 1GiB or GB by using the command :
#lvcreate — size 1GB — name partition-name vg-name
Now to confirm partition is created or not we use the command :
#lvdisplay vg-name/partition-name

Note: This time I am not using #udevadm settle before formatting this partition because we only use this command for RHEL8 O.S and here today I am using Amazon Linux 2 that’s why no need to use it.
Let’s do now format using command : #mkfs.ext4 /dev/arthvg/gc1

Now to mount firstly we will create a directory or folder because to interact to device storage user need a folder using this command: #mkdir /folder name
We will mount this using command : #mount /dev/vg-name/lv-name /foldername and by using #df -h command we can confirm it’s mounted inside/dev/mapper/arthvg-gc1 on folder /gulsha
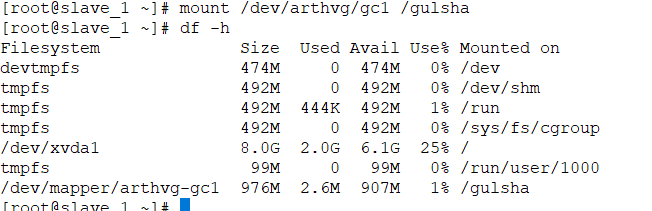
Technically we can say these all are link names/othernames/nicknames of LV
>> /dev/arthvg/gc1
>>dev/mapper/arthvg-gc1
>>/dm-0

Now the main benefit of LVM it is a dynamic partition here on the fly while doing something behind the scene we can increase/extend the size of the partition, on the other hand, it’s not possible to increase the size of the fixed partition. But, HOW?? Let me tell you about this amazing advantage of LVM😌
Step 2: Increase or Decrease the Size of dynamic partition in Linux using LVM storage.
We can extend the size of partition using command : #lvextend — size +2GB /dev/arthvg/gc1 here the volume is extended successfully we can confirm this by using #lvdisplay /dev/arthvg/gc1
Here a challenge comes in scenario🤔that we can see LV size is now 3GiB but while using #df -h it still shows 1GiB?Why so??🧐

Because while we were first time doing partition we formatted and mounted only 1GiB storage so now to increase size we need to reformat not by using mkfs.ext4 because this command will also remove our important data so to reformat we gonna use the command: #resize2fs /dev/arthvg/gc1 now no need to again mount it will automatically increase the size and we can confirm it by using #df -h command here -h means human-readable format because partition is always done in sectors, not in MB, GB, etc...

Hence,LVM Architecture is successfully created.
Now it’s time to contribute this storage of LVM to master node via data node.
Inside master node we can see it is taking storage from root folder(default) but we are gonna provide storage using LVM.

So let’s mount this storage of LV to /dn1 using command : #mount /dev/arthvg/gc1 /dn1

We can also confirm from master node using #hadoop dfsadmin -report

Finally our Task i.e TASK 7.1. A is successfully accomplished🥳🥳
Conclusion
In this task we made an HDFS cluster then we learned how to create LVM architecture and how instead of root folder master uses LVM storage. And we came to know that LVM helps to provide Elasticity to the Storage Device using a dynamic partition.
Thank you for reading my article🤗
Keep Learning🤩Keep Sharing🤝🏻
Good Day🤙🏻
